AUTOMATING CONTACT LOG SUMMARIES: ELIMINATING AFTER-CALL WORK WITH LLMs
At Essent, we process more than 1.6 million customer interactions each year across voice and live chat channels. After every interaction, whether it was about billing, a complaint, or a meter reading issue, customer service agents still had one task left before moving on to the next conversation.
They had to write a contact log entry.
Agents work in an internal application called Cockpit, where they manage customer information such as contact logs. After each conversation, they had to write a summary of the interaction and select the correct category and subcategory.
For every single conversation.
Across hundreds of agents working for Essent and Energiedirect, this adds up quickly. The work is repetitive, inconsistent between agents, and extends the time spent in After Call Work (ACW) before the next customer can be helped.
We decided to automate it.
The Solution
We built an automated process that listens for conversation-end events from Genesys Cloud, retrieves the conversation data, generates a summary using a GPT model, and pushes a structured contact log into our backend systems.
When an agent finishes a conversation, the contact log is already there. In most cases, it appears within 2–5 seconds.
The system supports both live chat and voice calls and runs entirely on AWS.
The pipeline is event driven. There are no scheduled jobs or polling loops. The system simply reacts when a conversation ends.
Impact
Before building the system, we estimated the potential impact based on historical interaction volumes and a conservative reduction in After Call Work.
At the time of writing, the contact center handles roughly:
~800,000 voice calls per year
~500,000 live chat conversations per year
Internal measurements showed that writing and categorizing a contact log typically takes around 40–60 seconds depending on the complexity of the conversation.
Using a conservative estimate of ~50 seconds saved per interaction, the potential reduction in manual work looks roughly like this:
Voice calls
800,000 calls × 50 seconds ≈ 11,100 hours per year
Live chat
500,000 chats × 50 seconds ≈ 6,900 hours per year
Combined, this results in roughly:
~18,000 hours of agent time saved annually
These numbers are estimates and will vary depending on interaction type and conversation complexity. In practice, this means agents can move to the next customer faster while still maintaining consistent documentation of customer interactions.
Example: From conversation to contact log
To illustrate how the system works in practice, below is a simplified example of a real conversation and the generated contact log.
Example conversation (chat)

Generated contact log

The generated output already matches the structure expected by the backend system. In most cases the agent does not need to edit the contact log at all.
System architecture
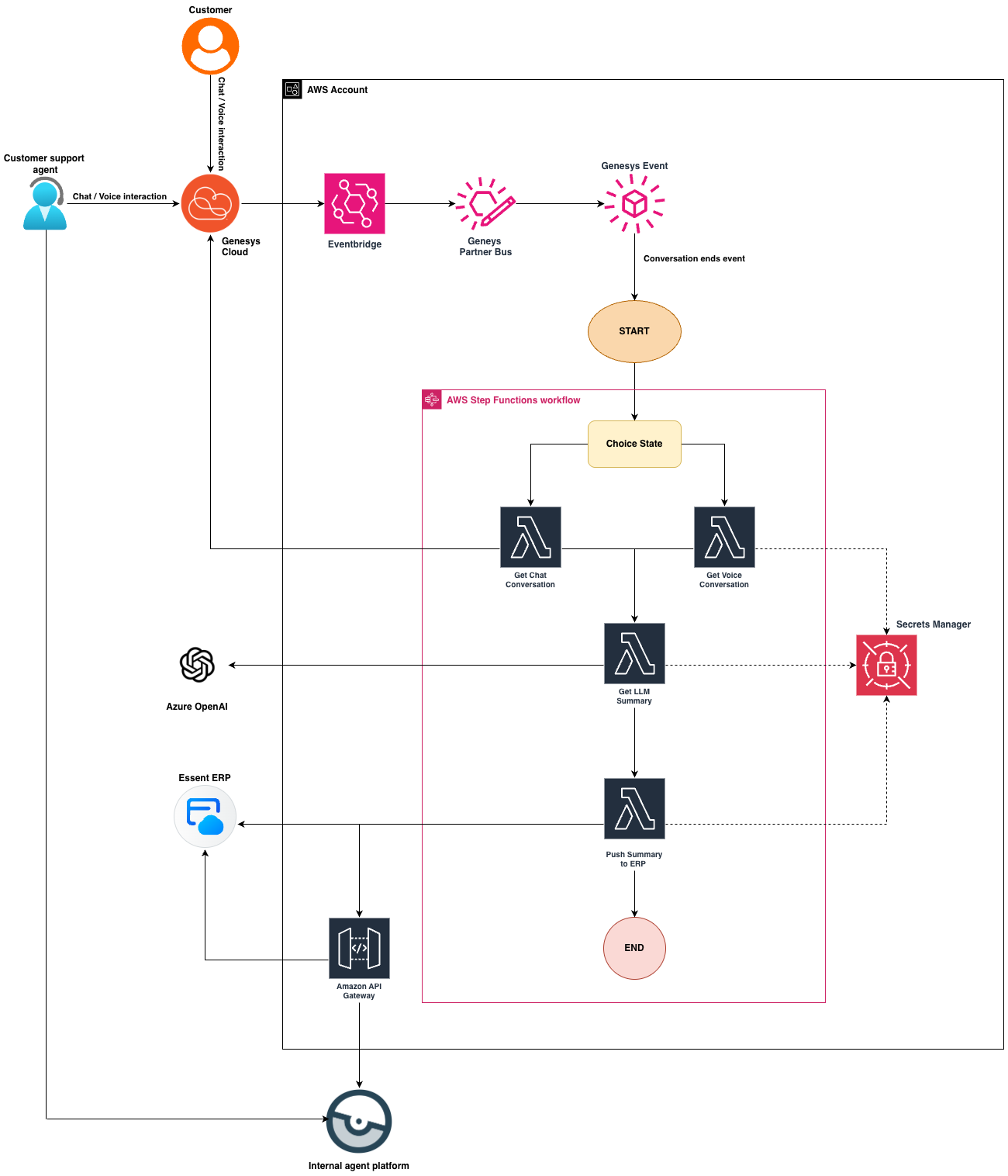
The system follows an event-driven serverless architecture. Each component is responsible for a single step in the pipeline: receiving the event, processing conversation data, generating the summary, and creating the final contact log.
Genesys Cloud emits events when conversations end. These events are delivered directly to AWS through an EventBridge Partner Event Bus. From there, the pipeline is triggered, and the conversation is processed automatically.
Using a serverless architecture allows the system to scale naturally with the volume of conversations. When interaction volumes increase, the pipeline simply processes more events in parallel without requiring additional infrastructure management.
How it works
The system is built as a fully event-driven pipeline.
When a conversation ends in Genesys Cloud, an event is emitted. Instead of polling for completed conversations, the system reacts directly to these events.
1. Conversation ends in Genesys Cloud
For chat interactions a conversation.user.end event is emitted. For voice calls, the event is triggered once the speech-to-text transcript becomes available.
2. Event ingestion
The event is delivered to an Amazon EventBridge Partner Event Bus which receives events directly from Genesys Cloud.
3. Pipeline trigger
An EventBridge rule invokes a small starter Lambda which starts an AWS Step Functions state machine. The conversationId is used as the execution name.
4. Conversation processing
The state machine routes execution to either a chat processing Lambda or a voice processing Lambda. Each function retrieves the conversation data from the Genesys APIs and transforms it into a clean dialogue format.
5. Conversation cleanup
Before summarization, the pipeline removes bot messages, system messages, and conversation noise, so the model only receives relevant dialogue.
6. LLM summarization
The cleaned conversation is sent to Azure OpenAI GPT model which generates a structured JSON response containing Description, Note, Category, and Subcategory.
7. Contact log creation
A final Lambda sends the structured contact log to the backend system for the appropriate brand (Essent or Energiedirect).
In most cases, the entire pipeline is completed within a few seconds after the conversation ends.
Architecture deep dive
Deduplication without extra infrastructure
EventBridge guarantees at-least-once delivery, meaning the same event may occasionally arrive more than once.
Instead of implementing a custom deduplication mechanism with DynamoDB, the system relies on a property of Step Functions: execution names must be unique.
By using the conversationId as the execution name, duplicate events simply trigger an ExecutionAlreadyExists error. The starter Lambda exits quietly and the existing pipeline execution continues.
This removes the need for additional infrastructure while still guaranteeing idempotent processing.
Processing only relevant conversations
Not every conversation should result in a contact log.
Before continuing the pipeline we verify that:
● a human agent was involved
● the customer account could be identified
● the customer was successfully authenticated
If one of these checks fails, the state machine exits early.
This keeps monitoring signals meaningful and prevents unnecessary processing.
Voice and chat are processed differently
Voice calls and chat conversations have very different data structures, so they are processed separately.
For chat conversations:
● messages are retrieved from the Genesys Conversations API
● bot messages before agent handover are removed
● Cognigy system messages are filtered out
For voice conversations:
● transcripts are retrieved from Genesys Speech & Text Analytics
● timestamped phrases are reconstructed into dialogue
● phrases are grouped by speaker role (agent and customer)
Both pipelines produce a clean dialogue format that the summarization model can interpret reliably.
The LLM Prompt
The prompt used for summarization is written in Dutch, the language used by both agents and most customers.
Example excerpt from the prompt:

Costs
Running a system like this is not free.
Voice conversations rely on the Genesys Speech & Text Analytics transcription feature which generates the transcripts used for summarization.
The AWS infrastructure also introduces runtime costs. The pipeline uses Lambda, Step Functions, and EventBridge which scales automatically but still incurs usage-based pricing.
Finally, each conversation summary is generated by GPT-4.1 mini hosted in Azure OpenAI, which is billed based on tokens processed.
Even when accounting for these costs, the automation remains economically beneficial compared to the thousands of hours of manual work it replaces.
Conclusion
Automating contact logs may sound like a small improvement. At the scale of a contact center handling more than a million conversations each year, the impact becomes substantial.
By combining event streaming from Genesys Cloud, serverless infrastructure on AWS, and LLM-based summarization, a repetitive manual task has been turned into an automated background process.
Agents finish a conversation and the contact log is already there.